













While the world of AI can often feel a bit like the wild west, there is a surprisingly high amount of analysis, benchmarking, and testing that goes on behind the scenes. Not just from the companies themselves, but from groups set up to establish their own rankings.
These groups test everything from a chatbot’s ability to complete mathematical tests, create images, show reasoning, offer medical advice, or simply how emotionally intelligent they are.
Across these different tests, models go up and down, showing their strengths and weaknesses in different areas. For example, while GPT-5 is great at scientific reasoning, it fell behind the likes of Gemini and Claude for its ability to adapt to new concepts.

Each of these tests tells us something new about AI models, and they are important as a reminder of which tool is best in different scenarios. But one measurement is often lacking. Simply, which AI models offer the best user experience?
The Humaine ranking system
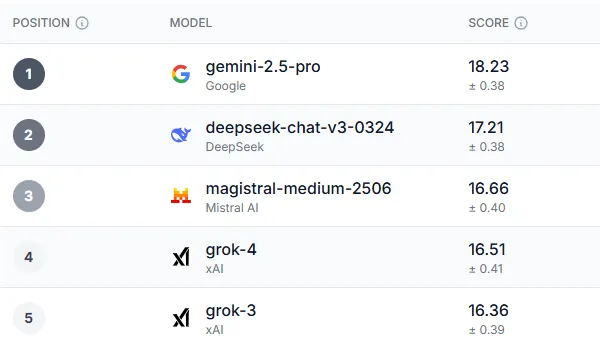
A UK-based tech company called Prolific has set up its own AI leaderboard called Humaine. Instead of testing AI’s ability to complete tasks, Prolific tested different users’ experiences of the models.
By evaluating 21,352 people’s experiences of 21,352 people with the tools, they could not only find an overall winner but also break down the results by age, location (tested in both the UK and the US), and political beliefs.
This includes individual lists for:
- UK: age groups
- UK: Ethnicity
- UK: Political view
- US: age groups
- US: Ethnicity
- US Political view
The team made each participant interact with two seperate AI models in a comparison, asking them to give feedback on which model was better in each interaction.
This led to an overall winner and scoreboard for performance, but also separate rankings for core task performance and reasoning, as well as a winner for communication, fluidity, and trust and ethics.
What do the results show?

After polling, there was a very clear winner, not just in the overall performance category but in most of the subcategories. Gemini 2.5-Pro came out on top in almost every filter that the test offered.
18-34 year olds in the UK, Democrat voters, and those over 55 in the US all agreed that Gemini 2.5 Pro was the best overall model. The only area that all demographic groups ranked something above Gemini was in trust, ethics, and safety was Grok-3 — a somewhat ironic finding considering some of the safety and ethics issues the AI model has had of late.
Interestingly, the three models that come up after Gemini are Deepseek, Magistral Le Chat, and Grok. While Deepseek saw a huge amount of popularity earlier this year, it has fallen off the radar recently. Le Chat, on the other hand, is a less popular chatbot, but one with a loyal fanbase.
So, where is the world-famous ChatGPT in all of this? It’s a big scroll down, coming in 8th with the GPT-4.1 model ranking highest. Even worse is Claude, with its two version 4 models landing 11th and 12th in the overall ranking.
So what does this all mean?
Does this mean Gemini is the best AI chatbot in the world? Does it mean you should be ditching ChatGPT…? Well, not exactly.
These results don’t necessarily reflect the performance of these models. When tested on most other metrics, the options we normally see at the top are ChatGPT, Gemini, Claude and Grok.
This, however, is an important addition to these tests. It helps to give a better understanding of AI from a more human experience perspective. Le Chat, for example, doesn’t score as highly in benchmarks, but is frequently listed as a top option for experience and trust.
While Anthropic and OpenAI don’t do too well in this particular round of testing, it is another strong performance for both Gemini and Grok. Both companies frequently score highly in benchmarks and have continued to do so here, too.
More from Tom's Guide
- I tested Pangram, the ‘black light’ of AI detection built by ex-Tesla and Google engineers — here's how well it worked
- I used Google's Nano Banana to try a bunch of different hairstyles — and the results blew me away
- This new AI tool can predict your risk of 1,000+ diseases — meet Delphi-2M











